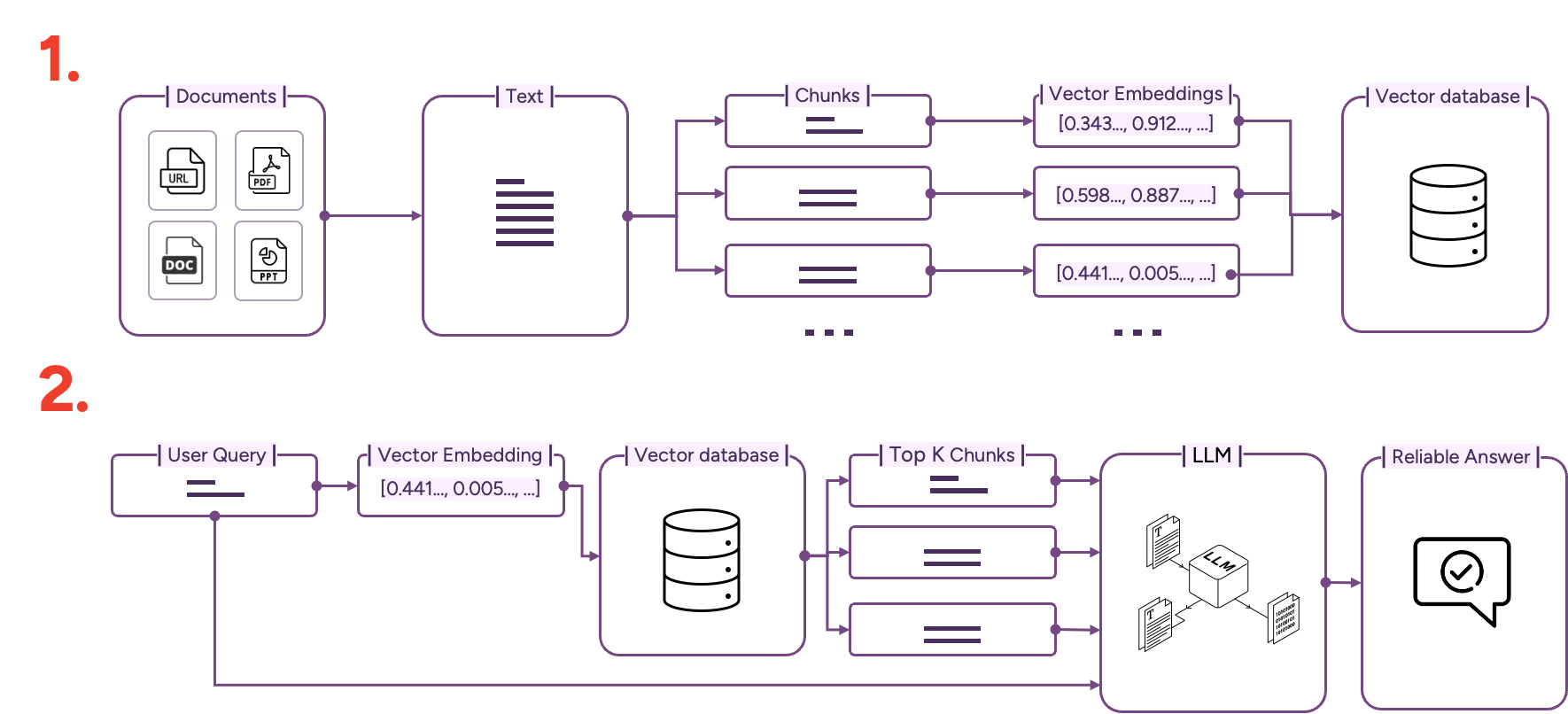
Optimizing accuracy
The basic Private GPT is already optimized to the most common Document types and RAG adapters (in progress; with every update and adapter we make, the model is expanded and enhanced). There will be automatic evaluations and judges implemented on the pipelines that score the method used, to optimize accuracy of the output. However, it can be that certain styles, documents or kinds of documents are not yet fully supported. A high accuracy can’t be achieved. When this is the case, we provide a Professional Service to optimize the pipeline in order to get a higher accuracy.
The Professional Service can be offered as Project or Retainer.
To determine the intensity and lead time of the Retainer, a number of factors have influence:
- Accuracy target (50+% ; 60+%; 70% and higher)
- Dedication of customer to test (number of questions, number of people available)
- Number of document-types
- Structure of documents / data sources
- Number of data-sources (data-adapters)
Added Value of Service - Optimize Accuracy of Output
Nebul is able to fine-tune the pipeline in order to optimize the accuracy of the output. This is done for each document-type and source-type (data-connectors).
- Questions that will be prompted
- Expected output
- Co-creation period, with Slack or Teams channel, to link our AI-expert to customers senior employees (with in-depth knowledge of was is being added to the model)
- Accuracy tests (from moment 0)
- Keeping track of improvements
- Keeping track of adjustments
Retainer
- Fine-tuning on
- Loader
- Chunker
- Embedding model
- Optimalisation on
- Hybrid Search & Reranking
- Feedback / Weighing
- Retraining
- Re-evaluation